
Normalizing Tables in SQL
So far in all SQL examples we were dealing with a single table. The truth is that in real life when dealing with databases you’ll have to work with many tables, which are interrelated. The true power of the Relational Database Management Systems is the fact that they are Relational.
The relationships in a RDBMS ensure that there is no redundant data. For example: An online store, offers computers for sale and the easiest way to track the sales will be to keep them in a database. We can have a table called Product, which will hold information about each computer - model name, price and the manufacturer. We also need to keep some details about the manufacturer like their website and their support email. If you store the manufacturer details in the Product table, you will have the manufacturer contact info repeated for each computer model the manufacturer produces:
The relationships in a RDBMS ensure that there is no redundant data. For example: An online store, offers computers for sale and the easiest way to track the sales will be to keep them in a database. We can have a table called Product, which will hold information about each computer - model name, price and the manufacturer. We also need to keep some details about the manufacturer like their website and their support email. If you store the manufacturer details in the Product table, you will have the manufacturer contact info repeated for each computer model the manufacturer produces:
| model | Price | Manufacturer | ManufacturerWebsite | ManufacturerEmail |
| Inspiron B120 | $499 | Dell | http://www.dell.com | support@dell.com |
| Inspiron B130 | $599 | Dell | http://www.dell.com | support@dell.com |
| Inspiron E1705 | $949 | Dell | http://www.dell.com | support@dell.com |
| Satellite A100 | $549 | Toshiba | http://www.toshiba.com | support@toshiba.com |
| Satellite P100 | $934 | Toshiba | http://www.toshiba.com | support@toshiba.com |
To get rid of the redundant manufacturer data in the Product table, we can create a new table called Manufacturer, which will have only one entry (row) for each manufacturer and we can link (relate) this table to the Product table. To create this relation we need to add additional column in the Product table that references the entries in the Manufacturer table.
A relationship between 2 tables is established when the data in one of the columns in the first table matches the data in a column in the second table. To explain this further we have to understand SQL relational concepts – Primary Key and Foreign Key. Primary Key is a column or a combination of columns that uniquely identifies each row in a table. Foreign Key is a column or a combination of columns whose values match a Primary Key in a different table. In the most common scenario the relationship between 2 tables matches the Primary Key in one of the tables with a Foreign Key in the second table. Consider the new Product and Manufacturer tables below:
A relationship between 2 tables is established when the data in one of the columns in the first table matches the data in a column in the second table. To explain this further we have to understand SQL relational concepts – Primary Key and Foreign Key. Primary Key is a column or a combination of columns that uniquely identifies each row in a table. Foreign Key is a column or a combination of columns whose values match a Primary Key in a different table. In the most common scenario the relationship between 2 tables matches the Primary Key in one of the tables with a Foreign Key in the second table. Consider the new Product and Manufacturer tables below:
Manufacturer
| ManufacturerID | Manufacturer | ManufacturerWebsite | ManufacturerEmail |
| 1 | Dell | http://www.dell.com | support@dell.com |
| 2 | Toshiba | http://www.toshiba.com | support@toshiba.com |
Product
| model | Price | ManufacturerID |
| Inspiron B120 | $499 | 1 |
| Inspiron B130 | $599 | 1 |
| Inspiron E1705 | $949 | 1 |
| Satellite A100 | $549 | 2 |
| Satellite P100 | $934 | 2 |
The first table is Manufacturer which has 2 entries for Dell and Toshiba respectively. Each of these entries has a ManufacturerID value, which is unique integer number. Because the ManufacturerID column is unique for the Manufacturer table we can use it as a Primary Key in this table. The Product table retains the Model and the Price columns, but has a new column called ManufacturerID, which matches the values of the ManufacturerID column in the Manufacturer table. All values in the ManufacturerID column in the Product table have to match one of the values in the Manufacturer table Primary Key (for example you can’t have ManufacturerID with value of 3 in the Product table, simply because there is no manufacturer with this ManufacturerID defined in the Manufacturer table).
Notice that we used the same name for the Primary Key in the first table as for the Foreign Key in the second. This was done on purpose to show the relationship between the 2 tables based on these columns. Of course you can call the 2 columns with different names, but if somebody sees your database for a first time it won’t be immediately clear that these 2 tables are related.
But how do we ensure that the Product table doesn’t have invalid entries like the last entry below:
Notice that we used the same name for the Primary Key in the first table as for the Foreign Key in the second. This was done on purpose to show the relationship between the 2 tables based on these columns. Of course you can call the 2 columns with different names, but if somebody sees your database for a first time it won’t be immediately clear that these 2 tables are related.
But how do we ensure that the Product table doesn’t have invalid entries like the last entry below:
| model | Price | ManufacturerID |
| Inspiron B120 | $499 | 1 |
| Inspiron B130 | $599 | 1 |
| Inspiron E1705 | $949 | 1 |
| Satellite A100 | $549 | 2 |
| Satellite P100 | $934 | 2 |
| ThinkPad Z60t | $849 | 3 |
We do not have a manufacturer with ManufacturerID of 3 in our Manufacturer table, hence this entry in the Product table is invalid. The answer is that you have to enforce referential integrity between the 2 tables. Different RDBMS have different ways to enforce referential integrity, and I will not go into more details as this is not important to understand the concept of relationship between tables.
There are 3 types of relations between tables – One-To-Many, Many-To-Many and One-To-One. The relation we created above is One-To-Many and is the most common of the 3 types. In One-To-Many relation a row in one of the tables can have many matching rows in the second table, but a row the second table can match only one row in the first table.
In our example, each manufacturer (a row in the Manufacturer table) produces several different computer models (several rows in the Product table), but each particular product (a row in the Product table) has only one manufacturer (a row in the Manufacturer table).
The second type is the Many-To-Many relation. In this relation many rows from the first table can match many rows in the second and the other way around. To define this type of relation you need a third table whose primary key is composed of the 2 foreign keys from the other 2 table. To clarify this relation lets review the following example. We have a Article table (ArticleID is primary key) and Category (CategoryID is primary key) table.
Every article published in the Article table can belong to multiple categories. To accommodate that, we create a new table called ArticleCategory, which has only 2 columns – ArticleID and CategoryID (these 2 columns form the primary key for this table). This new table called sometimes junction table defines the Many-To-Many relationship between the 2 main tables. One article can belong to multiple categories, and every category may contain more than one article.
In the One-To-One relation each row in the first table may match only one row in the second and the other way around. This relationship is very uncommon simply because if you have this type of relation you may as well keep all the info in one single table.
By dividing the data into 2 tables we successfully removed the redundant manufacturer details from the initial Product table adding an integer column referencing the new Manufacturer table instead.
The process of removing redundant data by creating relations between tables is known as Normalization. Normalization process uses formal methods to design the database in interrelated tables.
There are 3 types of relations between tables – One-To-Many, Many-To-Many and One-To-One. The relation we created above is One-To-Many and is the most common of the 3 types. In One-To-Many relation a row in one of the tables can have many matching rows in the second table, but a row the second table can match only one row in the first table.
In our example, each manufacturer (a row in the Manufacturer table) produces several different computer models (several rows in the Product table), but each particular product (a row in the Product table) has only one manufacturer (a row in the Manufacturer table).
The second type is the Many-To-Many relation. In this relation many rows from the first table can match many rows in the second and the other way around. To define this type of relation you need a third table whose primary key is composed of the 2 foreign keys from the other 2 table. To clarify this relation lets review the following example. We have a Article table (ArticleID is primary key) and Category (CategoryID is primary key) table.
Every article published in the Article table can belong to multiple categories. To accommodate that, we create a new table called ArticleCategory, which has only 2 columns – ArticleID and CategoryID (these 2 columns form the primary key for this table). This new table called sometimes junction table defines the Many-To-Many relationship between the 2 main tables. One article can belong to multiple categories, and every category may contain more than one article.
In the One-To-One relation each row in the first table may match only one row in the second and the other way around. This relationship is very uncommon simply because if you have this type of relation you may as well keep all the info in one single table.
By dividing the data into 2 tables we successfully removed the redundant manufacturer details from the initial Product table adding an integer column referencing the new Manufacturer table instead.
The process of removing redundant data by creating relations between tables is known as Normalization. Normalization process uses formal methods to design the database in interrelated tables.
NORMALIZATION EXAMPLE 1: EMPLOYEE PROJECT DETAIL
Given below is the data in an un-normalized table. Normalize it to 1NF, 2NF and 3NF.
DETAILS TABLE
Proj_no | Proj_name | Emp_no | Emp_name | Rate_category | Hourly_rate |
101 | AirLine Reservation | 1001 1002 1003 | John Smith Amit | A B C | 60 50 40 |
102 | Advertising Agency | 1001 1004 | Rahul Preeti | A B | 60 50 |
Solution:
Table in 1NF:
DETAILS TABLE
Proj_no | Proj_name | Emp_no | Emp_name | Rate_category | Hourly_rate |
101 | AirLine Reservation | 1001 | John | A | 60 |
101 | AirLine Reservation | 1002 | Smith | B | 50 |
101 | AirLine Reservation | 1003 | Amit | C | 40 |
102 | Advertising Agency | 1001 | Rahul | A | 60 |
102 | Advertising Agency | 1004 | Preeti | B | 50 |
The key is (Proj_no,Emp_no)
Functional Dependencies:
Proj_no -> Proj_name
Emp_no -> Emp_name, Rate_category, Hourly_rate
Transitive Dependencies :
Rate_category -> Hourly_rate
Tables in 2NF:
Emp_Proj Table
Proj_no | Emp_no |
101 | 1001 |
101 | 1002 |
101 | 1003 |
102 | 1001 |
102 | 1004 |
Employee Table
Emp_no | Emp_name | Rate_category | Hourly_rate |
1001 | John | A | 60 |
1002 | Smith | B | 50 |
1003 | Rahul | A | 40 |
1004 | Preeti | B | 50 |
Project Table
Proj_no | Proj_name |
1001 | Airline Reservation |
1002 | Advertising Agency |
Tables in 3NF:
Emp_Proj Table
Proj_no | Emp_no |
101 | 1001 |
101 | 1002 |
101 | 1003 |
102 | 1001 |
102 | 1004 |
Project Table
Proj_no | Proj_name |
1001 | Airline Reservation |
1002 | Advertising Agency |
Employee Table
Emp_no | Emp_name | Rate_category |
1001 | John | A |
1002 | Smith | B |
1003 | Rahul | A |
1004 | Preeti | B |
Rate Table
Rate_category | Hourly_rate |
A | 60 |
B | 50 |
C | 40 |
NORMALIZATION EXAMPLE 2 :DEPARTMENT COMPLAINTS
Important Assumption
Assume that the Dept. # and Cust. # are all needed to uniquely identify the date and nature of the complaint about the department.
Step 1: Identify Dependencies
Draw lines showing the dependencies between each attribute
Unnormalized Table
Dept# | Dept Name | Loc | Mgr Name | Mgr id Name | Tel Extn. | Cust# | Cust Name | Date of comp | Nature of comp |
11232 Soap Cincinnati Mary S11 7711 P10451 Robert 1/12/1998 PS Division Samuel Drumtree P10480 Steven 1/14/1998 DAParks | |||||||||
Step 2:Convert UNF to 1NF
When moving from an Unnormalized table to 1NF, take out repeating groups. One approach is to fill in empty cells. A second is to split out the repeating elements into a new table.
In this case, I removed the fields that were repeating.
1NF Table(s)
| Dept # | Cust # | Cust Name | Date of Complaint | Nature of Complaint | Dept Name | Location | Mgr | Mgr ID No. |
Step 3:Convert 1NF to 2NF
To move a table from 1NF to 2NF, remove partial dependencies.
In this case, the Customer Name depends only on Cust#, which is a partial dependency. Therefore remove the Customer Name and make a copy of Cust #
2NF Tables
Dept# | Cust# | Date Of Complaint | Nature Of Complaint |
Dept# | Dept Name | Location | Mgr Name | Mgr ID No. | Tel Ext. |
Cust# | Cust Name |
Step 4:Convert 2NF to 3NF
To move a table from 2NF to 3NF, remove transitive dependencies.
In this case, the Mgr Name is dependent on the Mgr ID No., which is a transitive dependency. Therefore, remove the Mgr Name and make a copy of the the Mgr ID No.
3NF Table
Dept# | Cust# | Date Of Complaint | Nature Of Complaint |
Dept# | Dept Name | Location | Mgr Name | Mgr ID No. | Tel Ext. |
Cust# | Cust Name |
Mgr Id No | Mgr Name |
- Drill downThe concept of drill-down analysis applies to the area of data mining to denote the interactive exploration of data, in particular of large databases. The process of drill-down analysis begins by considering some simple break downs of the data by a few variables of interest (e.g., gender, geographic region, etc.). Various statistics, tables, histograms, and other graphical summaries can be computed for each group. Next, you may want to "drill-down" to expose and further analyze the data "underneath" one of the categorizations; for example, you might want to further review the data for males from the Midwest. Again, various statistical and graphical summaries can be computed for those cases only, which might suggest further break-downs by other variables (e.g., income, age, etc.). At the lowest ("bottom") level are the raw data: For example, you may want to review the addresses of male customers from one region, for a certain income group, etc., and to offer to those customers some particular services of particular utility to that group.What are variables? Variables are things that we measure, control, or manipulate in research. They differ in many respects, most notably in the role they are given in our research and in the type of measures that can be applied to them.Categorical and continuous variables. The nature of the variables selected for the drill-down operation can be categorical or continuous. For categorical variables the categories to choose from for the next drill-down operation are (usually) directly available in the data (e.g., a variable Gender with categorical values Male and Female); for continuous variables a number of different methods for dividing the range of values into categories are available: you can request a certain number of categories into which to divide the range of values in the continuous drill-down variable, you can specify the step size for consecutive categories, or you can specify specific boundaries for the continuous drill-down variables. For example, for a continuous variable Income, you could set up specific (income) "brackets" of interest to your project, and then drill down on those brackets to review the distributions of variables within each bracket.
Impact of too many Variables
- Course of Dimensionality
- Data Mining performance
- Deployment complexity
- Capitalizing on chance
Course of Dimensionality
· For each added predictor variable in data mining model the number of data points needed grows rapidly.· Before analysis, variables known to be unnecessary as well as those that add a small amount information should excluded from analysis.· This is partially important for Neural Networks.Data Mining Performance
Prescreening input variable can improve data mining performance with respect to :· Model building speed.· Predictive accuracy of data mining models.
Deployment complexity
- Each predictor used by the data mining model is required to deploy that model to new case.
- If good predictive accuracy is attainable with smaller number of inputs, deployment is made easier.
Capitalizing on chance
- When using traditional statistical methods such as general linear Models, be cautious in testing the hypothesis that a particular variable is significant in the model or not.
- These hypothesis tests should be interpreted with care.
Variable Screening
Why screen Variables for analysis
§ Not all variables that are collected will be important in the analysis§ Some variables more difficult to monitor than others (time consuming & costly).§ More simple models are easier to deploy.§How to select variables
§ Select a specific number of variable.§ Select base of significance tests.

Data Sampling and Sample Size
· Dividing data into train, test and validation sample· What sampling Accomplishes· Methods of sampling· Sample Size
Sample
· Train – used to create models and find patterns· Test- prevents the models from learning helping the model to generalize the new cases· Validation-estimating and compares performance of models. Hold -out data from model building.
What Sampling Accomplishes
· Using a random sample, the pattern and relationships between variables in the population are present in the sample· Using a sample makes the computation run much quickly· Safeguard against “over-fitting” the data using test and validation samples

Methods of Sampling
· Subset and Random sampling tools in statistica· Assign cases to samples via spreadsheet formulas.
Sample Size
· The accuracy with witch the patterns in the sample will reflect the patterns of the population is a function of sample size, not population size.· Correlation between two variable computed from a sample of 1,000 will reflects the population correlation with the sample accuracy, whether taken from a population of 100,000 or 100,000,000.Stratified Random Sampling
· A Stratified Random Sample selects specified proportions from each group of the strata variables.· With the proportion of outcomes even, model building will give appropriate focus to the rare events
Problem Cause by Missing Data
· Some data mining algorithms cannot handle missing data. The cases with missing data are ignored.· Cases with missing data contain valuable information for the other variable. Ignoring these cases lost of information possibly biased results.
Missing Data Substitution
1. Common missing Data Substitution
· Mean· Median· Specific ValuesA potential issue with these methods is artificially decrease variance.2. K Nearest Neighbors
· The user select a value K· The k cases most similar to the one with missing data are use to fill in the missing observation.· Each missing data cases is filled in with a value found specifically for it.
Data Cleaning – Other Data Issues
· Sparse variables and cases· Invariant variables· Duplicated records
How to resolve Sparse Data (cases with too many missing values)
· A variable will not provide beneficial information to the model if we don’t enough observation for it.· A case with to many missing entries no longer adds tangible information to the model
Invariant Data
· A variable with very little or no variability does not add anything to the model· These variables should be removed
Duplicated Data
· Duplicated records can be artificially weight those duplicated cases in the analysis· Say a customer has apply for a loan multiple times and is listed in the data set multiple times.· If the duplicates are not removed this individual will have greater influence in the model.
Type of Data Mining applications
§ Classification§ Regression§ Clustering
Classification

1. In a Classification type problem we have a variable of interest which is categorical in nature. For Example
· Classification of credit risk. either good are bad· Classifying patients as high risk for heart disease· Classifying individuals as high risk for heart disease2. The goal of the classification problem can include· Finding variable that are strongly related to the variable of interest· Developing a predictive model where a set of variables are used to classify the variable of interest ‘y’.Regression

1. In Regression Type of problem we have a Variable of interest which is continuous in nature for example it could be· A measurement for the manufacturing process· Revenue in dollars· Decrease in cholesterol after taking the meditation2. The goal of regression problems are similar to classification and it includes· Finding variable that are strongly related to the variable of interest· Developing a predictive model where a set of variables are used to classify the variable of interest ‘y’.
Clustering

1. In clustering type of problem, there are no traditional variable of interest. instead the data need to store into cluster for example· Clustering individual for marketing companies· Clustering symptoms in medical research to find relationship· Finding clusters of brands, based of the customer responses2. The goal of cluster analysis problem includes· Finding variables that are most highly influence cluster assignment· Comparing the cluster across variable of interest· Assigning new cases to cluster and measuring the strength of cluster membership
Consider a hypothetical case of data set for different mining operations:-
CreditScoring.sta
Variables used in the data set are:1. Credit rating2. Balance of current account3. Duration of credit4. Payment of preview credits5. Purpose of credit6. Amount of credit7. Value of saving8. Employed by current employee for9. Installation in % of Available income10. Marital Status11. Gender12. Living in current Household for13. Most valuable Assets14. Age15. Further running credits16. Type of apartment17. Number of previous credits at this bank18. Occupation19. Train/TestContinuous variable:- 3, 6 & 14Categorical variable:- 1, 2, 4, 5, 7, 8, 9, 10, 11, 12, 13, 15-19
Steps to make bundles of variables:-- Select Data.
- Select Bundle manager.
- Click new.
- Name the bundle & click ok.
- Add variables by selecting the variables in this bundle.
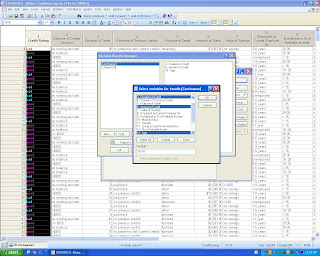
Continuous Variable Bundle
Categorical Bundle Variable
Steps to drill down a variable of a data set1. Select Data Mining menu.2. Select Data Mining- Workspace3. Select General Slicer/Dicer Explorer with drill down4. Further select Interactive drill down. A dialog box appears


6. Select histogram button to review the variable under consideration.
To make histogram1. Select Graph menu.2. Select histogram option.3. Dialog box appears.
4. Press Ok and histogram appears.
To make scatter plot1. Select Graph menu.2. Select scatter plot option.3. Dialog box appears. Select appropriate variables from the list of variables.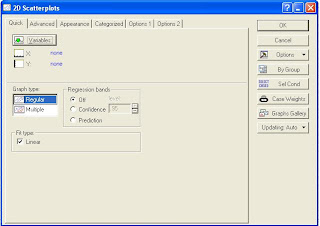

4. Press ok.
Box plot and Outlier Analysis1. Select the column indicating the variable under consideration. For example ‘Amount of credit’.2. Select Graph menu.3. Select ‘Graphs of Input data’ option.4. Select ’graph whiskers by’ option. Box plot for the variable selected appears.
For age box plot is
In order to remove outliers1. Select View menu.2. Select brushing menu. A dialog box appears.3. In extended tab select the range. In the current example the age above 60 years is considered outliers. So it is specified in brushing range.

4. Select the interactive tab and clicks apply. Box plot is modified by removing outliers.
Another way to remove outliers is through filtering.Data Filtering1. Select data menu.2. Select data Filtering/Data recoding option.3. Select ’recode outlier’. Dialog box appears

4. Press Ok and outliers will be marked red in the dataset as shown in the sample below.
Box plot if built again will be similar to box plot displayed above after brushing.
Sort the variable.1. Let the given data set i as shown below.
2. Sort the attribute under consideration by selecting data menu.3. Select sort menu. Dialog box appears. Select variable you want to sort. ‘Payment of previous credit’ as selected below.
4. All the rows will be sorted with respect to variable selected. Sorted result will be
Data Filtering-To removes duplicates1. The data set has to be sorted w.r.t the variable you want to filter. If you want to filter the data ’Payment of previous credit’ sort the data for the variable. Select the variable.2. Select data menu.3. Select data filtering. From the submenu select ‘Filter duplicate cases’.4. A dialog box appears.

5. Press Ok and duplication of data for that variable will be removed as shown below.
To process missing data1. If the given data set is as under
2. Select the variable.3. Select data menu.4. Select data filtering menu. From the submenu select ‘Process missing data’.5. A dialog box appears.

6. Recode action. Type of missing-data filtering to be performed; missing data codes can be replaced with a user-specified value, medians, means, or cases with missing data values can be discarded altogether. If case selection conditions are in effect, these will be applied to the computation of means, medians, etc.7. Recode value. Specifies a value to use as the replacement for missing data; this option is only used if Replace with specific value was selected as the Type of MD filtering.8. If it is selected as ‘Recode MD to mean’ it will replace missing variable values with mean of the values available in that variable. It is shown below.
9. In case you want to fill missing values by any constant select ‘Recode MD to value’ from the drop down menu shown above.10. Add any constant value in Recode value option. Example it is 66 in this case.
11. Press Ok and missing values will be filled with 66.
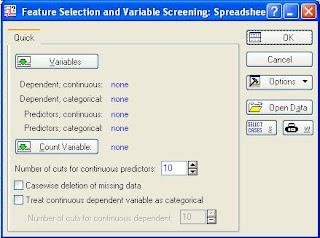
Data Mining – Feature Selection and Variable Screening
Select Feature Selection and Variable Screening from the Data Mining menu to display the Feature Selection and Variable Screening dialog. This module will automatically select subsets of variables from extremely large data files or databases connected for in-place processing (IDP). The module can handle a practically unlimited number of variables. Literally millions of input variables can be scanned to select predictors for regression or classification.Specifically, the program includes several options for selecting variables ("features") that are likely to be useful or informative in specific subsequent analyses. The unique algorithms implemented in the Feature Selection and Variable Screening module will select continuous and categorical predictor variables that show a relationship to the continuous or categorical dependent variables of interest, regardless of whether that relationship is simple (e.g., linear) or complex (nonlinear, non-monotone). Hence, the program does not bias the selection in favor of any particular model that you may use to find a final best rule, equation, etc. for prediction or classification. Optionally, after an initial (unbiased) screening and feature selection step, further post-processing algorithms can be applied, based on CHAID, C&RT, MARSplines, Neural Networks, and linear modeling methods, to derive a final list of predictors.Various advanced feature selection options are also available. This module is particularly useful in conjunction with the in-place processing of databases (without the need to copy or import the input data to the local machine), when it can be used to scan huge lists of input variables, select likely candidates that contain information relevant to the analyses of interest, and automatically select those variables for further analyses with other nodes in the data miner project. For example, a subset of variables based on an initial scan via this module can be submitted to the STATISTICA Neural Networks feature selection options for further review. These options allow STATISTICA Data Miner to handle data sets in the giga- and terabyte range.1. Select data mining menu.2. Select ‘feature selection and variable screening’ option.3. Dialog box appears.
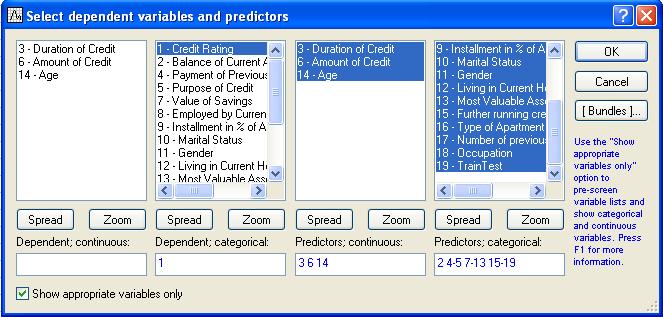
4. Press Variables
5. To show appropriate variables only select that check box. Above box changes to the form as shown below. Appropriate continuous and categorical dependent variables and predictors will be shown.
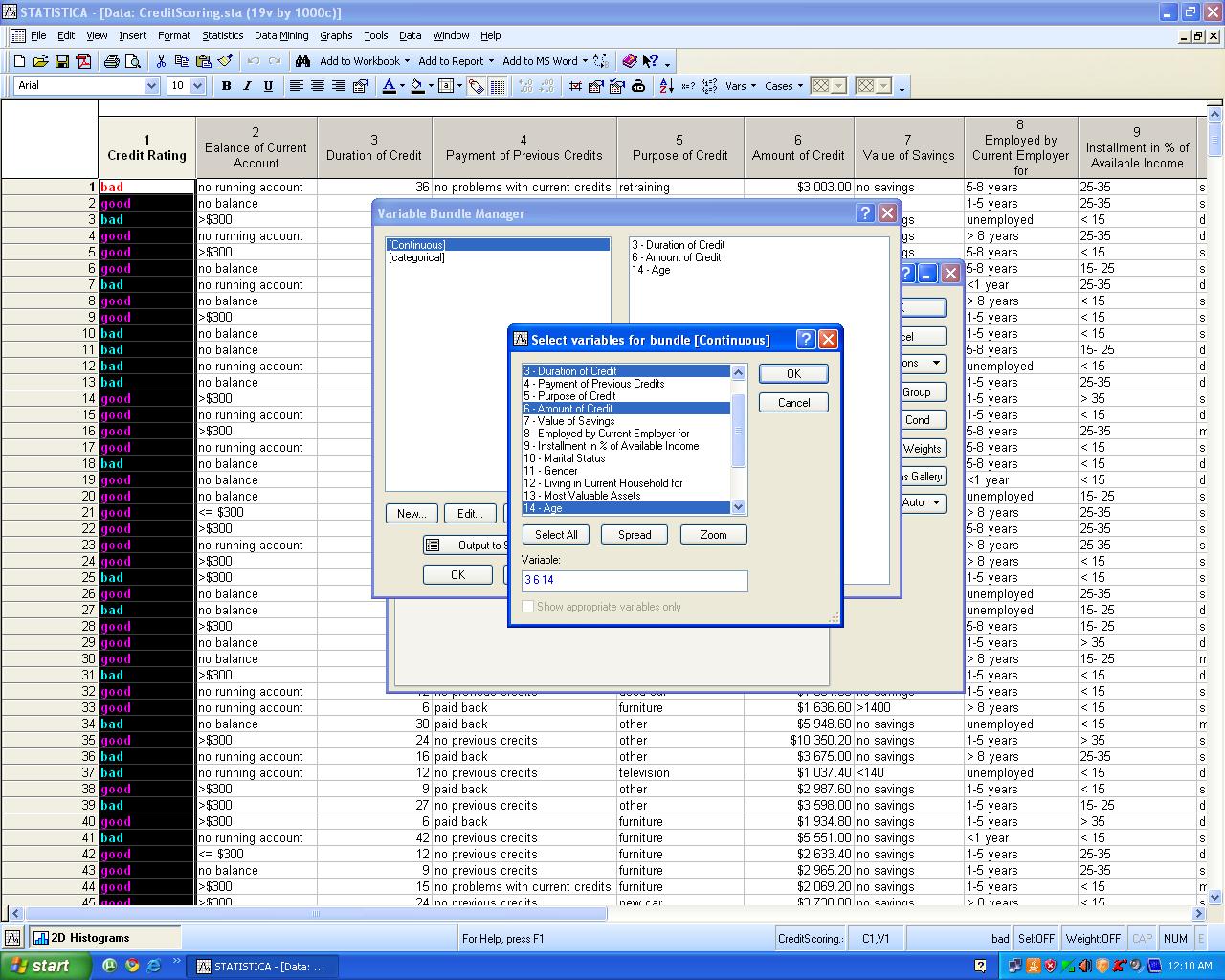
To bundle variables together so that they could be referenced by a single name.6. Select bundle button. Dialog box appears.
7. Select new button. Dialog box appears. Write name of the new bundle and press OK.8. A new box appears.
9. Select variables for this bundle and click ok.10. The bundle appears with the list of variables in given screen.

11. Select appropriate dependent and predictor variables and press OK.12. A dialog box appears.

13. Click ‘Histogram of importance for best k predictors’. Histogram appears.

14. Select ‘Summary best k predictors’ button. Following dialog box appears.

Random sampling1. Select data menu.2. Select ‘subset/random sampling’ from menu. A dialog box appears.
3. Select appropriate variables for sampling. Let for the current scenario we want to use all the variables.4. For simple sampling select ‘simple random sampling’ radio button. Insert approximate percentage of sample you want. Say in this case it has been selected 2% out of 1000 records.
5. To make use of simple random sampling with replacement select check box ‘With replacement’.
6. Press Ok and the sample with replacement will be as shown below.
7. To make use of stratified sample select tab for that. Following box appears.
8. Click ‘strata variables’ button. List of all the variables appears. Select the appropriate variable. In this case it is selected to be ‘Balance of current account’. Click Code button. Following box appears. Select All button to get all the strata for the current variable.
9. Press Ok and following box appears.
10. Either make approximate selection for each strata or click ‘Uniform Probability’ check box and fill same approximation for all the strata.
11. Press Ok and following sample appears.
C&RT Specifications
Select Quick specs dialog as the Specification method on the General Classification and Regression Trees Startup Panel - Quick tab and click the OK button to display the C&RT Specifications dialog. This dialog contains five tabs: Quick, Classification, Stopping, Validation, and Advanced. In practically all cases, the most efficient way to write C&RT syntax is to use the Quick specs dialog, and then click the Syntax editor button in that dialog to "translate" the selected specifications to the command syntax. This can further be edited and updated as and when required.OK. Click the OK button display the run the analysis and display the C&RT Results dialog. Note that if you have not already specified variables, a variable selection dialog will first be displayed when you click this button.Cancel. Click the Cancel button to close the dialog without performing an analysis.Options. Click the Options button to display the Options menu.Select Cases. Click the Select Cases button to display the Analysis/Graph Case Selection Conditions dialog, which is used to create conditions for which cases will be included (or excluded) in the current analysis. More information is available in the case selection conditions overview, syntax summary, and dialog description.W. Click the W (Weight) button to display the Analysis/Graph Case Weights dialog, which is used to adjust the contribution of individual cases to the outcome of the current analysis by "weighting" those cases in proportion to the values of a selected variable.Syntax editor. Click the Syntax editor button to display the General Classification and Regression Trees Syntax Editor dialog, which contains various options for specifying designs and for modifying various parameters of the computational procedures. You can also open an existing text file with command syntax, or save syntax in a file for future repetitive use. Refer to the General Classification/Regression Tree Models Syntax Overview for additional details. Note that selecting Analysis syntax editor automatically moves the Type of analysis selection to C&RT with coded design.1. Select Data mining menu.2. Select ‘General Classification and Regression tree model’. Following dialog box appears.
3. Make appropriate selection and press OK. Dialog box appears.
4. Click Variable button and make appropriate selections. Press OK.
5. Following box appears.
6. Select Tree browser. Following box appears.
7. If data is as shown below.
8. Select Data mining menu.9. Select ‘General Classification and Regression tree model’. Following dialog box appears.
10. Make appropriate selection and press OK. Dialog box appears.
11. Click Variable button and make appropriate selections. Press OK.
12. Press Ok and following box appears.
13. Press Tree graph button and following result displayed.
14. Press tree layout button and following screen appers.
15. Press ‘scrollable tree’ button. Following scrollable tree appears.
16. Press ‘Tree structure’ button following screen appears
17. On pressing button ‘Terminal Node’ following screen appears.
18. On pressing ‘Cost Sequence’ button following screen appears
19. On pressing V-fold and cross validation sequence following screen appears.
To modify variables1. Select data menu.2. Select ‘Variable Specs’ from the menu. Following dialog box appears.
3. We can modify name, type or other properties of the attribute from this screen.4. In order to modify all the variables select ‘All Variable Specs’ option. Following screen appears.
Add a new variable1. To add, move, copy or delete a variable select data menu and then variable menu.2. Select appropriate option from sub menu appeared.3. To create a new variable following screen appears.

MeanThe mean is a particularly informative measure of the "central tendency" of the variable if it is reported along with its confidence intervals. Usually we are interested in statistics (such as the mean) from our sample only to the extent to which they are informative about the population. The larger the sample size, the more reliable its mean. The larger the variation of data values, the less reliable the meanMean = ( xi)/n Where n is the sample size.
xi)/n Where n is the sample size.
Steps to find Mean :1. Go to Statistics Menu.2. Go to Statistics of block Data.3. Select Block Columns if you want to find various Statistical value of a particular column(s).4. Select Block Rows if you want to find various Statistical value of a particular row(s)

Output of Mean of Amount of Credit :
MedianA measure of central tendency, the median (the term first used by Galton, 1882) of a sample is the value for which one-half (50%) of the observations (when ranked) will lie above that value and one-half will lie below that value. When the number of values in the sample is even, the median is computed as the average of the two middle values.
Steps to find Median :1. Go to Statistics Menu.2. Go to Statistics of block Data.3. Select Block Columns if you want to find various Statistical value of a particular column(s).4. Select Block Rows if you want to find various Statistical value of a particular row(s)
Output of Median of Amount of Credit:
Standard DeviationThe standard deviation (this term was first used by Pearson, 1894) is a commonly-used measure of variation. The standard deviation of a population of values is computed as: = [(xi-µ)2/N]1/2 Where µ is the population mean
= [(xi-µ)2/N]1/2 Where µ is the population mean
N is the population size.
The sample estimate of the population standard deviation is computed as:s = [(xi-x bar)2/n-1]1/2 where x bar is the sample mean
n is the sample size.
Steps to find Standard Deviation :1. Go to Statistics Menu.2. Go to Statistics of block Data.3. Select Block Columns if you want to find various Statistical value of a particular column(s).4. Select Block Rows if you want to find various Statistical value of a particular row(s)

Output of Standard Deviation of Amount of Credit :
Chi-square distributionIn probability theory and statistics, the chi-square distribution (also chi-squared or χ²-distribution) with k degrees of freedom is the distribution of a sum of the squares of k independent standard normal random variables. It is one of the most widely used probability distributions in inferential statistics, e.g. in hypothesis testing, or in construction ofconfidence intervals.
Steps involved :- Go to data mining tab and select feature selection & variable screening.
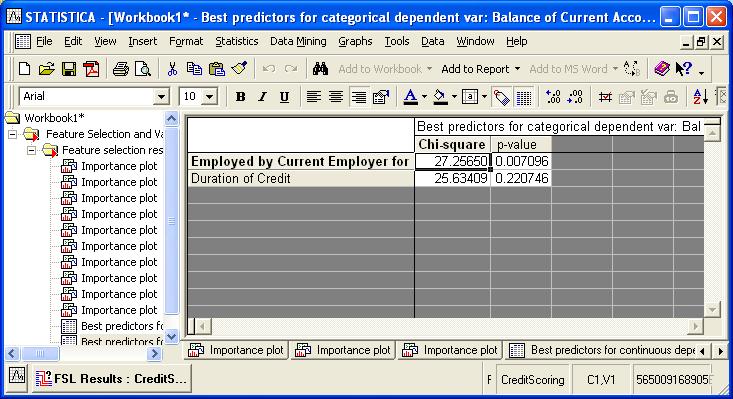
- Click variables button and select credit rating as dependent variable and all other variables as predictors. Press ok.
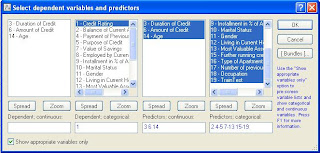
- Enter 17 as best display predictors

- Click on summary to get chi-square values

- Go to histogram of importance for best K predictors

- Course of Dimensionality
















































































No comments:
Post a Comment